Одноранговая синхронизация
Нужно стремиться к тому, чтобы системы, участвующие в синхронизации, знали друг о друге как можно меньше. Чем меньше системы должны знать о других системах, тем проще их подключать и отключать от общего контура.
Например, желательно, чтобы система, запрашивающая данные, делала это в формате своих сущностей (использовала свои названия сущностей, имена реквизитов в них). Преобразованием форматов должны заниматься специальные адаптеры, которые настраиваются централизованно в агрегирующем сервисе (координаторе синхронизации).
Каждая система может сообщать о произошедших в ней изменениях данных. Делает она это путём выгрузки этих изменений в AGR. При этом она выгружает данные в своих терминах, она не должна знать в какую именно систему она их выгружает, в каком формате и с какой полнотой (состав выгружаемых реквизитов) система-получатель ожидает эти данные. Преобразование формата данных входит в задачи координатора синхронизации (AGR). Принимать решение о том, какие из полученных данных нужно загружать, а какие игнорировать, должна система-получатель.
Если в AGR задана конвертация для какой-либо сущности, он её применяет. Если конвертация не задана, сущность передаётся в том формате, в каком поступила. Можно задать конвертацию, которая полностью исключит какую-то сущность из сообщения. Это может быть полезно для снижения нагрузки, если известно, что система не должна получать эту сущность.
На веб-сервис конечной системы приходят запросы двух видов:
-
listRequest, elmentRequest -- Запросы на выгрузку данных из системы. Эти два вида запросов устроены очень похоже, отличаются лишь глубиной сериализации данных, которые они возвращают. listRequest выполняет неглубокую сериализацию. Он предназначен для получения списка элементов. Отдельные элементы после этого можно запросить во всех подробностях запросом elementRequest.
- updateRequest -- Используется для приёма конечной системой широковещательных сообщений об изменениях, произошедших с данными в других системах. Система получатель сама решает, что делать с информацией из этого сообщения. Какие-то элементы могут быть загружены, какие-то обновлены, что-то может быть проигнорировано.
Данные могут быть запрошены:
- По уникальному идентификатору (UID) и виду сущности (например, Справочники.Контрагенты). В запросе можно передавать список элементов. Все они будут выгружены в одно ответное сообщение.
- Можно запросить выгрузку всей сущности. В одном запросе можно указывать несколько сущностей. Этим нужно пользоваться осторожно, так как объём данных может оказаться большим.
- Можно передать текст запроса, возвращающий список элементов, которые должны быть сериализованы.
Поле entityName для систем 1С содержит строки вида Тип.Вид, где Тип - это тип элемента ("Справочники", "Документы"), а Вид - вид элемента. Например, "Справочники.Контрагенты".
Поле специально сделано одно, так как в общем случае, содержащийся в нём описатель сущности может иметь другой формат, например, не содержать точки.
Для участия в одноранговой синхронизации каждая система должна использовать идентификаторы элементов в формате GUID. Это ограничение связано с тем, что УИДы используются в самом формате передаваемых сообщений. В целом, из-за глобальной уникальности УИДы являются наиболее удобным способом идентификации.
У каждой системы есть два варианта идентификации своих элементов с точки зрения синхронизации: по первичному ключу или по дополнительному реквизиту, содержащему синхронизационный УИД. Более сложные варианты я решил пока не рассматривать, так как мы с ними не сталкивались. Но подозреваю, что они могут быть сведены к одному из двух предложенных выше.
У каждого варианта есть свои особенности:
| Синхронизация по первичному ключу | Синхронизация по дополнительному реквизиту |
|---|---|
| Доступен конечной системе, если она является изначальным источником для данной сущности. Либо, если на момент начала синхронизации в получающей системе нет элементов данной сущности. | Доступен в любой момент, даже если система начинает участвовать в синхронизации когда в ней уже имеются элементы. |
| Два элемента в разных системах считаются идентичными, если их первичные ключи совпадают. | Допускает возможность уникально идентифицировать пару Система-Элемент без использования составного ключа. |
| Значения первичного ключа уникальны, пустые значения ключа не допускаются. | Значения синхронизационного реквизита уникальны, но могут существовать элементы, для которых синхронизационный реквизит не заполнен. |
| При сериализации объектов в качестве идентификатора элемента в сообщении будет использоваться первичный ключ. | При сериализации объектов в качестве идентификатора элемента в сообщении будет использоваться значение синхронизационного реквизита. Если реквизит пуст, выгрузка элемента недопустима. |
| При десериализации сообщения поиск элементов будет осуществляться в первичном ключе по УИД из сообщения. | При десериализации сообщения поиск элементов будет осуществляться в синхронизационном реквизите. |
Только конечная система должна знать, какой вариант синхронизации используется для каждой её сущности. Если рассмотреть синхронизацию одного конкретного элемента, принцип прост: для синхронизации элемента используется всегда одно конкретное значение УИД данного элемента, но каждая система, в которой этот элемент может присутствовать, может хранить его либо в первичном ключе, либо в синхронизационном реквизите.
На первый взгляд, описанный подход противоречит требованию выгружать данные в формате самой системы. Но он является значительно более простым по сравнению с альтернативой (принимать решение, что является ключом синхронизации для каждой системы на уровне координатора AGR).
- Да, при таком подходе каждая система должна сама знать, что в ней является ключом. Но она и не может этого не знать. Ведь именно в рамках системы принимается решение, где будет ключ. Если он будет в реквизите, реквизит создаётся.
- Если в какой-то сущности ключом является дополнительный реквизит, данная система не может сделать запрос elementRequest по данному элементу в собственном формате без усложнения формата сообщений. Ведь при запросе в собственном формате, система должна указать свой УИД из первичного ключа, который не является синхронизационным.
- Если система и так должна принимать это решение, нет никакого смысла усложнять этим же аспектом координатор синхронизации.
Для подключения конечной донор-системы 1С необходимо добавить несколько объектов в конфигурацию этой системы.
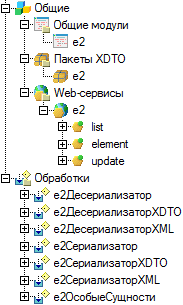
Пакеты XDTO: e2 -- Содержит пространство имён http://agr.glance.ru/e2, которое используется во всех сообщениях системы синхронизации. С этим пространством имён работает веб-сервис e2.
Web-сервисы: e2 -- Веб-сервис, принимающий три вида обращений: listRequest, elementRequest и importRequest. Веб-сервис нужно будет опубликовать на каком-нибудь веб-сервере.
Роли: Web -- Роль, для которой прописаны разрешения на обращения к функциям веб-сервиса e2. Если в системе существует уже роль, предназначенная для вызова веб-сервисов, можно задействовать её, но нужно будет прописать разрешения на доступ к функциям веб-сервиса e2.
Общие модули: e2 -- Общий модуль, для которого установлены галочки Серверный и Привилегированный. Вызовы, которые приходят на веб-сервис e2 перенаправляются в данный модуль. Дело в том, что заранее не известно, доступ к каким данным понадобится в результате обращения к веб-сервису, а, значит, либо нужно дать пользователю веб-сервиса полные права, либо выполнить вызов в привилегированном режиме.
Над правами и безопасностью стоит ещё подумать.
Обработки: extПоискЭлементов -- обработка-дополнение, инкапсулирующая методы для поиска элементов, по которым будет выполняться сериализация. Вызывается из модуля e2 при обработке запросов на получение данных listRequest и elementRequest.
Обработки: extСериализатор -- обработка-дополнение, инкапсулирующая методы для сериализации ссылок на элементы в объекты XDTO, либо в XML. Вызывается из модуля e2 при обработке запросов на получение данных listRequest и elementRequest.
Обработки: extСериализаторXDTO -- обработка-дополнения, реализующая методы сериализации в XDTO-объекты. Экземпляр этой обработки передаётся в качестве параметра обработке extСериализатор.
Обработки: extДесериализатор -- обработка-дополнение, реализующая методы десериализации сообщений. В настоящий момент она используется из модуля e2 для десериализации некоторых объектов XDTO. В дальнейшем она будет полностью отвечать за десериализацию, скрывая слой XDTO или XML.
Обработки: extОсобыеСущности -- необязательная обработка-дополнение. В ней могут объявляться методы в специальном формате, которые могут отвечать за сериализацию или поиск элементов сущностей по индивидуальным правилам. Модуль e2, если находит обработку с таким именем в конфигурации, инициализирует её и передаёт в обработки extПоискЭлементов и extСериализатор в качестве параметра. Типичным примером индивидуального поиска элемента является случай, когда сущность синхронизируется не по первичному ключу, а по дополнительному реквизиту.
Каждая конечная система должна знать идентификатор и название данного экземпляра (базы данных). Идентификатор должен быть в формате 36-символьной строки UUID. Например:
| UUID | Название экземпляра |
|---|---|
| 0dc4995e-c3a9-11e6-820f-005056912b96 | Казначейство Боевая "Банджо" |
| cea59306-de62-11e6-9327-005056914a36 | Казначейство Боевая "Гранж" |
Приведённые примеры имеют одинаковую конфигурацию, но так как это разные экземпляры, у них разные идентификаторы и названия.
Идентификатор и наименование должно устанавливаться в методе createSystemResponse общего модуля e2.
Функция createSystemResponse(use, response)
ДополненнияЭкземпляры = Дополнения().Создать("ЭкземплярыБаз");
systemResponse = use.createXDTO("systemResponse");
systemResponse.systemUid = ДополненнияЭкземпляры.ПолучитьСтрокуUID();
systemResponse.systemName = ДополненнияЭкземпляры.ПолучитьНаименованиеЭкземпляра();
response.systemResponse.Добавить(systemResponse);
Возврат systemResponse;
КонецФункцииФрагмент взят из конфигурации "Казначейство", в нём используется дополнение ЭкземплярыБаз для получения идентификатора и наименования. В другой конфигурации это может быть организовано иначе.
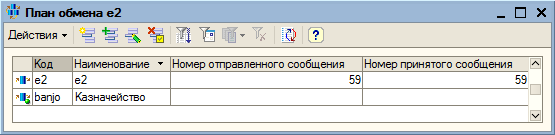
Если система должна быть источником обновлений, в ней необходимо организовать регистрацию изменений для тех сущностей, об изменении которых она должна сообщать наружу. Для 1с-систем в этих целях предусмотрен план обмена e2.
Кроме внедрения плана обмена e2 в конфигурацию, необходимо также создать узел в этом плане обмена. Рекомендую не мудрить и назвать новый узел e2. Собственный узел можно назвать по своему усмотрению. Например, для Казначейства получилось так:
Настройка для URL. В базе Розницы настройка URL к серверу Agr хранится в константе ПараметрыОтчетовПоМагазинам. Это ХранилищеЗначения, в которое записывается структура. В структуре один из ключей называется RestServiceE2, под ним и хранится URL к REST-сервису Agr.
Особенные сущности:
| Имя сущности | Особенности |
|---|---|
| Справочники.ФизическиеЛица | УИД для синхронизации находится в реквизите УИДЗУП. |
1С при сериализации через XDTO даты в XML записывает в таком формате:
<attribute attributeName="ДатаНачалаОтгрузок">
<value>2008-01-07T00:00:00</value>
</attribute>Интересно, сможет ли он их загрузить автоматически из такого формата?
Если не предоставлен специализированный метод для десериализации сущности, используется универсальный десериализатор для данного типа сущности (Справочника или Документа).
При стандартной десериализации ведущая роль принадлежит полученному сообщению. Десериализатор проходит по реквизитам, содержащимся в сообщении, и обновляет соответствующие реквизиты элемента.
Особенности универсальной десериализации:
- Обновляются только те реквизиты, которые имеются в сообщении, все остальные реквизиты элемента остаются неизменными.
- Если в сообщении встречается реквизит, отсутствующий в элементе, возникает исключение и обработка сообщения прерывается.
- Если на основании метаданных и информации сообщения о значении данного реквизита не удаётся установить его тип, обработка сообщения прерывается исключением.
- При десериализации не проводится различие между группами и элементами справочника. Поля обновляются в соответствии с сообщением. Учитывать различие между элементом и группой нужно только в случае конверсии в AGR.
Если перечисленные выше особенности не позволяют десериализовать элемент некоторой сущности стандартным десериализатором, есть два варианта: написать специализированный метод десериализации, либо реализовать конверсию сообщения на сервере AGR.
Чтобы обеспечить слабую связанность систем, вся конвертация сообщений должна происходить в AGR, каждая система должна получать сообщения в формате своих сущностей.
Конверсия определяется функцией:
(Тип-Системы-Входящего, Тип-Системы-Выходящего, Имя-Сущности-Входящего) -> КонверсияКонверсия может поступать с данными по своему усмотрению. Но, как правило, обработка одной конверсии фокусируется на одной входящей сущности. Если нужно добавить в выходное сообщение ссылку на другую сущность, конверсия может попросить менеджер конвертации сделать это. А менеджер отыщет нужную конверсию и применит его к элементу по ссылке.
В самом простом случае одна исходная сущность превращается в одну целевую сущность. При этом целевая сущность может называться иначе и иметь отличный состав реквизитов.
Самая простая разновидность этого случая -- копирование, при этом не меняется ни название сущности, ни состав реквизитов. В частности, если для маршрута и сущности конверсия не задана в явном виде, по умолчанию будет применена копирующая конверсия.
Бывают случаи, когда одна и та же исходная сущность может, в зависимости от значения некоторого реквизита, соответствовать разным целевым сущностям. В таком случае исходную сущность можно условно назвать "универсальной", а целевую -- специализированной. Конверсия должна уметь различать условия выбора и формировать на выходе нужную сущность, с нужным набором реквизитов.
В редких случаях встречается ситуация, когда одна исходная сущность в целевой системе должна состоять из двух или более сущностей, связанных ключом. Конверсия должна при этом сгенерировать на выходе элементы для всех необходимых целевых сущностей.
На один входной элемент в каждой выходной сущности может быть не более одного элемента. Это требование необходимо, чтобы можно было детерминировано работать с выходным результатом. В принципе, его можно не соблюдать, делать более одного элемента в какой-либо выходной сущности, но только один из элементов в связке с именем сущности может быть реферирован в качестве результата конверсии.
Этот тип конверсии является противоположностью конверсии "Split". Вероятно, в таком случае нужно будет использовать две (или более) избыточные конверсии для каждого вида входящих сущностей.
Эта конверсия означает, что элемент, являющийся сущностью в исходной системе, в целевой системе отдельной сущностью не представлен. В результате применения конверсии он превратится в скалярное значение, которое может быть записано в реквизиты других целевых сущностей.
Факт применения скалярной конверсии говорит о потенциальной возможности рассинхронизации систем (в случае изменения значащего реквизита сущности, приводимой к скаляру).
Что делать, если есть необходимость десериализовать сущность по-разному, в зависимости от того, какая система является источником сообщения?
Зависимость алгоритма десериализации от системы источника является плохой практикой, так как способствует усилению связанности систем. Специальной поддержки для этого сейчас в системе нет и, скорее всего, не будет. Рекомендуется использовать в таких случаях специальные методы десериализации для сущностей, но зависящие не от системы-источника, а от самих данных. В крайнем случае, из специального метода десериализации можно добраться до информации о системе-источнике, так как в метод передаётся узел из сообщения.
Возможно, также, что дополнение сообщений должно быть задачей агрегирующего сервиса.